



- Compartir










¿Qué es Hadoop de Apache? (vs. Spark)
¿Qué es Hadoop de Apache? (vs. Spark)
La tecnología del big data crece de manera imparable, ofreciendo así cada vez mayores oportunidades de negocio gracias a la explotación inteligente de datos por parte de las empresas. El inconveniente es que, con su crecimiento, el big data también se vuelve más complejo. En este contexto nace lo que es Hadoop, un ecosistema capaz de soportar las exigencias del big data al ofrecer capacidades que solucionan sus problemas de escalabilidad.
Grandes empresas han utilizado Hadoop para mejorar el procesamiento de sus datos. Por ejemplo: Facebook, IBM, eBay, LinkedIn, Twitter, AOL y Mercadolibre. Estas referencias hacen que sea indispensable conocer qué es Hadoop, para qué sirve y cómo funciona.
¿Qué es Hadoop de Apache?
Hadoop es un proyecto de código abierto desarrollado por la Apache Software Foundation. Se trata de un framework de software que permite programar aplicaciones distribuidas, es decir, aplicaciones capaces de trabajar con enormes cantidades de nodos en red y de datos.
Para profundizar en lo que es Hadoop de Apache y cómo funciona, este se basa en distribuir los datos y paralelizar el procesamiento de los mismos, de modo que cada nodo de una red de máquinas se encargue de procesar una parte de la totalidad de los datos durante el procesamiento del big data. A este método se le conoce como procesamiento distribuido o computación distribuida, que es, básicamente, distribuir las cargas de trabajo entre varios nodos de una misma red computacional. De aquí que Hadoop sea tan importante en la implementación del big data.

¿Para qué sirve Hadoop?
El big data se caracteriza por el procesamiento de grandes volúmenes de datos, que se generan a gran velocidad y que provienen de fuentes muy variadas. Por ejemplo, con un sistema de big data en las empresas, los gerentes pueden:
- Entender mejor a sus clientes. Esto es posible al recoger y procesar grandes cantidades de datos provenientes de redes sociales, páginas web, aplicaciones móviles, entre otras fuentes. Al analizar dichos datos, se puede detectar de manera detallada los gustos, deseos, necesidades y tendencias de miles o millones de usuarios. A partir de dicha detección, es posible entonces predecir comportamientos futuros en el mercado, diseñar mejores estrategias de marketing, desarrollar mejores productos o servicios, etc.
- Optimizar los procesos de negocio. Al obtener datos de múltiples fuentes (sistemas empresariales, proveedores, clientes, departamentos, etc.), una empresa de logística puede, por ejemplo, replantear sus procesos en la cadena de suministro para ahorrar costos, adaptar los niveles de stock en función de la previsión de la demanda para evitar el almacenamiento excesivo, mejorar las rutas de distribución para aprovechar al máximo cada unidad de transporte, diseñar líneas de producción mucho más eficientes, entre otros.
- Mejorar la productividad del personal y de las maquinarias. A través de sensores y otros dispositivos electrónicos, el sistema de big data logra extraer datos tanto de todos los empleados de la empresa como de las maquinarias que están instaladas. Al analizar dichos datos, los gerentes logran identificar patrones de comportamiento o de tareas que afectan la productividad. Por tanto, con esta información en mano, se pueden crear estrategias para aumentar los niveles de rendimiento del personal y de las máquinas, ya sea haciendo que los procesos se puedan ejecutar en un menor tiempo, redistribuyendo de manera inteligente al personal en planta para acortar su recorrido de un punto a otro, incluso planteando jornadas de trabajo mucho más coordinadas y eficientes, entre otros.
En este entorno tan exigente en cuanto a volumen, velocidad y variedad de datos, Hadoop se encarga de aportarle al sistema mayor rapidez, escalabilidad y tolerancia a fallos, para que la implementación del big data pueda funcionar de manera adecuada en las empresas.
Para lograrlo, Hadoop distribuye las cargas de trabajo con el fin de aportar mayor rapidez, permite agregar nuevos nodos al clúster de máquinas cada vez que el sistema necesita más potencia (escalabilidad), y garantiza la tolerancia a fallos debido a la alta disponibilidad y a la redundancia de los datos, los cuales suelen tener replicación 3 en el HDFS (Hadoop Distributed File System). Es decir, cada bloque de datos se almacena en 3 máquinas distintas al mismo tiempo.
¿Cómo está compuesto el ecosistema Hadoop?
El ecosistema de lo que es Hadoop está compuesto por los siguientes módulos:
- Hadoop Common: es un paquete de utilidades comunes entre los otros módulos. Este paquete contiene los archivos y los scripts necesarios para ejecutar Hadoop, así como también dispone del código fuente y de toda la documentación del proyecto Apache Hadoop.
- Hadoop Distributed File System: es el sistema de archivos distribuido que proporciona acceso de alto rendimiento a los datos de la aplicación. Este sistema se encuentra instalado en cada una de las máquinas, y es donde se almacenan los datos distribuidos.
- Hadoop YARN (Yet Another Resource Negotiator): comenzó siendo un gestor de recursos que precisamente controlaba todos los recursos distribuidos en todas las máquinas de la red, pero ahora es considerado un sistema operativo distribuido para aplicaciones de big data.
- Hadoop Ozone: es el almacén de objetos de Hadoop que se caracteriza por ser escalable, redundante y distribuido.
- Hadoop MapReduce: es un sistema basado en Hadoop YARN para el procesamiento paralelo y distribuido de grandes data sets (conjunto de datos).
¿Cómo funciona lo que es Hadoop MapReduce?
Al definir lo que es Hadoop, es importante entrar en detalle en el funcionamiento de MapReduce. MapReduce es la columna vertebral de Apache Hadoop. Este consiste en una técnica de procesamiento de datos que aplica dos tipos de funciones sobre los mismos: función map y función reduce.
La función map toma los archivos almacenados en el HDFS, y crea varios conjuntos de datos a partir de ellos. Después, la función reduce procesa esos conjuntos de datos y crear a partir de ellos conjuntos todavía más pequeños, los cuales se vuelven a almacenar en el HDFS. La secuencia de ambas funciones es la que facilita el procesamiento paralelo en lo que es Hadoop, ya que permite que el código se pueda ejecutar en múltiples nodos.
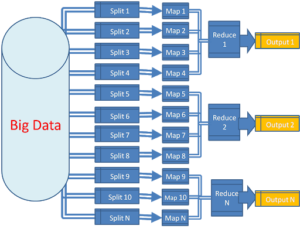
Fuente: Spider Opsnet
Java vs. Python en Hadoop (junto a MapReduce)
Java es el lenguaje de programación por defecto de lo que es Hadoop. Sin embargo, es posible utilizar Python, en vez de Java, para la ejecución de MapReduce.
Los pros y los contras de ambos lenguajes varían en función de cada proyecto de Hadoop. Por un lado, Java permite obtener la máxima potencia del CPU. Por otro lado, Python permite ahorrar energía, haciendo que los tiempos de desarrollo sean más rápidos.
También, al ser el lenguaje por defecto, con Java se puede desarrollar todo el proyecto en el mismo ecosistema. En el caso de Python, hay que comenzar el proceso de MapReduce por separado y después integrarlo al sistema, aunque el rendimiento de este lenguaje ha sido muy superior en diferentes contextos.
En resumen, se puede seguir utilizando Java para la ejecución del código de Hadoop, pero las funciones de map y reduce se pueden escribir primero en Python y después ejecutarlas en el sistema de Apache Hadoop. De esta manera, se logra un equilibrio para aprovechar lo mejor de cada lenguaje.
Comparativa de lo que es Hadoop vs Spark
Al igual que Hadoop, Spark es un proyecto de código abierto desarrollado por la Apache Software Foundation. En este contexto, Apache Spark surge como una evolución de lo que es Hadoop para optimizar los procesos de big data.
La principal característica, y diferencia con Hadoop, es que Spark no se basa en MapReduce para el procesamiento de datos, ya que este último resulta algo lento e ineficiente cuando se necesita un procesamiento en tiempo real.
Mientras que MapReduce ejecuta las tareas en modo lote y además utiliza el disco para los resultados intermedios, Spark en cambio ejecuta las tareas en microlotes y utiliza la memoria (no el disco). Esto hace que el procesamiento de datos sea mucho más rápido. De hecho, la velocidad de procesamiento de Spark es 100 veces más rápida en comparación a Hadoop cuando se ejecuta en memoria y 10 veces más rápida cuando se ejecuta en disco.
Sin embargo, es importante destacar que Apache Spark debe apoyarse en el sistema de ficheros distribuido de Hadoop (HDFS), ya que no cuenta con su propio sistema. Además, su potencia es mayor cuando también utiliza los otros módulos de la arquitectura de Hadoop.
En conclusión, para obtener un rendimiento óptimo al trabajar con big data, es recomendable hacer un uso combinado de lo que es Hadoop y lo que es Spark. De manera, es posible aprovechar el poder de Hadoop y la eficiencia de Spark.


- Compartir
Suscríbete a nuestro newsletter y no te pierdas nada
Te puede interesar

Cómo usar la IA para mejorar la experiencia de tus clientes (y fidelizarlos)
Leer más


 Inicio de sesión
Inicio de sesión  Capacitaciones gratuitas
Capacitaciones gratuitas Vitrina para tu negocio
Vitrina para tu negocio Redes de Contactos
Redes de Contactos Contenido exclusivo
Contenido exclusivo Regístrate
Regístrate Regístrate
Regístrate
 Mi Cuenta
Mi Cuenta Mi perfil
Mi perfil Mis favoritos
Mis favoritos Contáctanos
Contáctanos Cerrar sesión
Cerrar sesión Selecciona Categoría
Selecciona Categoría